ELMo

ELMo (от англ. Embeddings from Language Models) — метод Векторного представления слов для представления последовательности слов в виде последовательности векторов.[1] ELMo был разработан учеными из Института искусственного интеллекта Аллена и Вашингтонского университета в 2018 году.
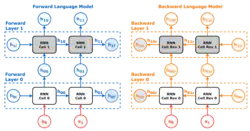
Архитектура ELMo основана на двунаправленных LSTM и использует входные данные на уровне символов для создания контекстуально-чувствительных встраиваний слов. Это делает ELMo полезным для задач обработки естественного языка, таких как разрешение кореференции и определение смысла слов в контексте (например, различение омонимов).
Архитектура
ELMo включает многослойную двунаправленную LSTM, которая накладывается на слой встраивания токенов. Входная последовательность сначала преобразуется в векторные представления с помощью слоя встраивания. Затем применяются два параллельных процесса:
- Прямой (forward) LSTM анализирует токены с учётом контекста предыдущих слов.
- Обратный (backward) LSTM анализирует токены с учётом последующих слов.
Результаты каждого слоя объединяются и проецируются в финальное представление размерностью 512.
ELMo был предварительно обучен на корпусе из 1 миллиарда слов. После предобучения модель может быть дообучена под конкретные задачи, что делает её одной из первых моделей, реализовавших подход «предобучение — дообучение».
Контекстуальная репрезентация слов
Одной из ключевых особенностей ELMo является способность учитывать контекст. Например, слово «банк» в предложениях:
- «She went to the bank to withdraw money.»
- «The birds are sitting one the bank.»
будет иметь различные представления в зависимости от контекста.
Историческая значимость
ELMo сыграл важную роль в развитии моделей обработки текста. В отличие от ранее популярных методов, таких как Word2vec и GloVe, ELMo создаёт уникальные представления для слов, исходя из их контекста. Модель также стала важным шагом к появлению BERT и других трансформерных архитектур.
Примечания
- ↑ Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018). Deep contextualized word representations. arXiv:1802.05365.